Usporedna analiza velikih jezičnih modela
Microsoft Research je predstavio rezultate usporedbe LLM-ova na različitim jezicima, modalitetima, modelima i zadacima


Veliki jezični modeli (LLM) u mnogim su zadacima i mjerilima nadmašili prethodne generacije jezičnih modela, približili se ljudskim performansama, a ponekad ih čak i nadmašili. No, još uvijek nije sasvim jasno što se krije iza tih impresivnih vještina: poboljšane mogućnosti modela, kontaminacija u testnim skupovima podataka ili nedostatak skupova podataka koji točno procjenjuju njihove sposobnosti.
Značajan nesrazmjer
Većina dosadašnjih studija koje su pokušale procijeniti LLM-ove primarno su se usredotočile na engleski jezik. No, novo istraživanje Microsoft Researcha otkriva značajan nesrazmjer u LLM-ovom poznavanju engleskog jezika u usporedbi s drugim jezicima. Međutim, vrednovanje LLM-a na drugim jezicima osim engleskog predstavlja brojne izazove, uključujući nedostatak višejezičnih mjerila za zaključivanje, razgovor i dijalog u različitim jezičnim obiteljima.
Nalazi iz ranijih studija daju vrijedan uvid u višejezične mogućnosti LLM-a. U usporedbi s najsuvremenijim prilagođenim jezičnim modelima poput TULRv6, GPT-4 pokazuje superiornu izvedbu. No, GPT modeli pokazuju lošiju izvedbu, posebno oni dizajnirani za jezike s malo resursa i jezike pisane pismom koje nije latinično.
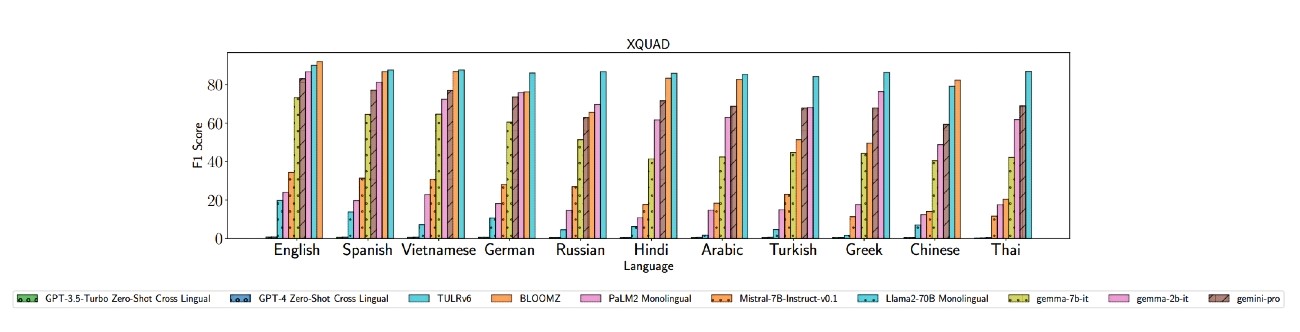
Microsoftovi istraživači proširili su pokrivenost na 22 skupa podataka i 83 jezika, uključujući mnoge afričke jezike s malo resursa, nadogradnjom na MEGA mjerilu i dodavanjem šest novih skupova podataka.
Fino podešavanje
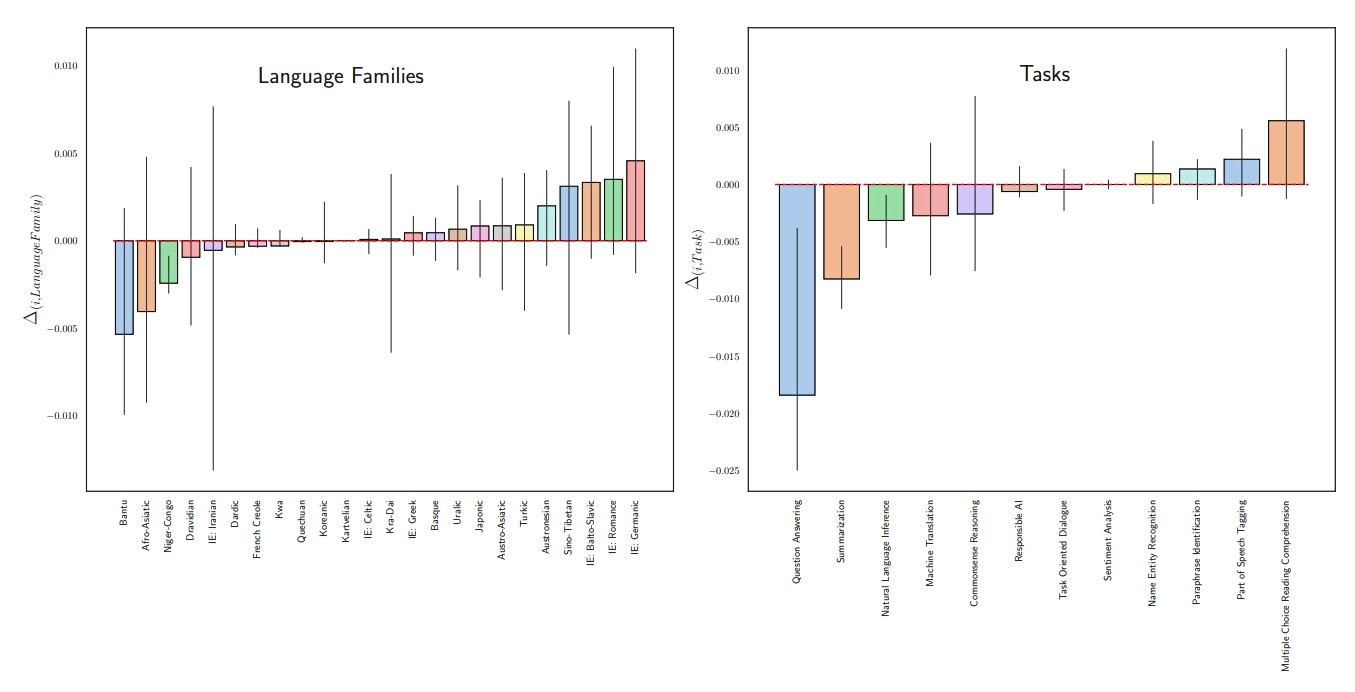
Ovaj rad pruža vrijedne uvide programerima i istraživačima. Konkretno, pokazalo se kako veći komercijalni modeli poput GPT-4 i Gemini-pro postižu bolje rezultate od manjih poput Gemme, Llame i Mistrala na jezicima s malo resursa.
Takav obrazac postoji u većini ispitivanih skupova podataka, što ukazuje da manji modeli imaju poteškoća s višejezičnom izvedbom. Da bi se poboljšala višejezična izvedba, sugeriraju istraživači, trebat će dodatno poraditi na finom podešavanju, modelima koji se temelje na obitelji jezika i modelima specifičnima za jezik.
Multimodalni skupovi podataka
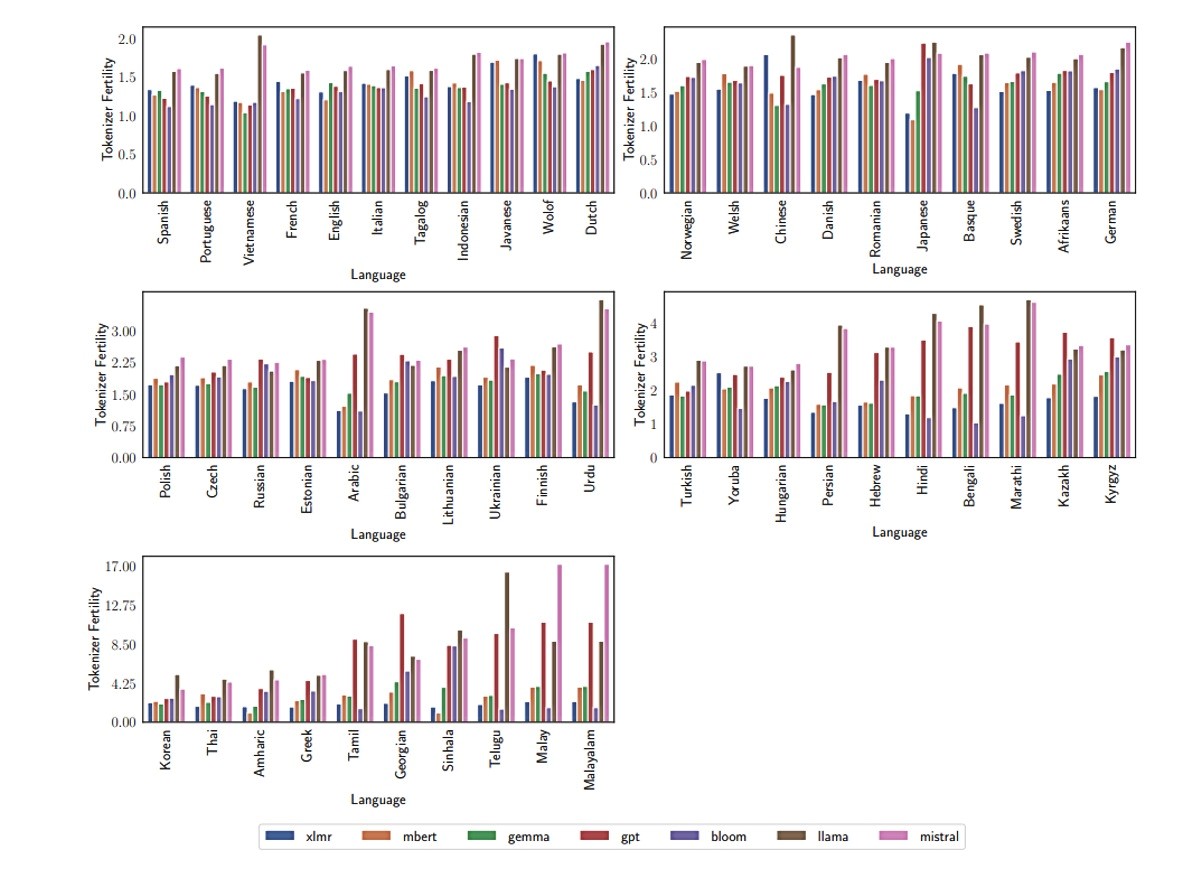
Što se tiče multimodalnih skupova podataka, pokazalo je istraživanje, GPT-4-Vision pokazao se boljim od LLaVA i Gemini-Pro-Vision, a učinkovitost jezičnog modela povezana je s plodnošću tokenizatora. Rad sugerira da je plodnost tokenizatora niža za jezike latiničnog pisma poput engleskog i španjolskog nego za morfološki komplicirane jezike poput telugua, malajskog i malajalamskog.
Zbog računskih i vremenskih ograničenja, istraživači nisu istražili kontaminaciju na svim skupovima podataka nego samo na 7B varijacijama modela otvorenog koda. Kontaminacija skupa podataka glavni je problem s usporednim studijama koje se provode na jezicima koji nisu engleski. Istraživači stoga namjeravaju poboljšati svoje kapacitete za otkrivanje kontaminacije i što bolju implementaciju zaštitnih mjera.























